
第2回目のテーマは、「Jenkinsによるテストポイントの自動挿入」です。DTシリーズでは、「時間計測」「カバレッジ計測」「CPU負荷やタスクの占有率」これら全てを「テストポイント」によって計測しています。DTシリーズと「テストポイント」は切っても切れない関係にあると言えます。言い換えれば、DTシリーズの機能を生かすも殺すも「テストポイント」の挿入の仕方次第ということになります。単純な例ではありますが、テストポイントの数が多ければ、欲しいデータが大量のデータに埋もれてしまって、何をテストした結果なのかわからなくなるケースもあります。逆に、テストポイントの数が少なければ、一部のテストの目的ははたせたとしてもそれで十分であったのか判断がつきません。DTシリーズ製品の特徴を十分に活かすためにも、テストの目的と内容と合った最適な「テストポイント挿入」が望まれています。
さて、このような「テストポイント」ですが、今回のテーマは「Jenkinsによるテストポイントの自動挿入」です。Jenkinsを使用することでテストポイント挿入のCI化は比較的容易に行えますが、「テストポイント挿入」をCI化するとき押さえておきたいポイントがあります。今回は、この押さえるべきポイントとあわせてどのような観点で「テストポイントの挿入」から「テスト結果のアウトプット」までをシナリオ設計すればよいか、ご紹介したいと思います。
CONTENTS
動的テストのためのCI環境とは
動的テストツールをCI(Continuous Integration)環境に組み込んだときの流れを、DTシリーズ製品を例に考えてみましょう。図1は、動的テストに必要な一連のCIサイクルを、Jenkins上で回したときの各処理の手順を表したものです。これらの一連の手順をJenkinsのJobとして登録しておき、ソースコードを構成管理ツールにコミット時もしくはある決まった時間に、登録したJobを実行させるのが一般的です。Jobが実行されることで、Jenkinsは自身のワークスペース上で構成管理ツールからソースコードを取得し、必要に応じてコードインスペクション(コーディングチェックや静的解析の実施)を行い、対象ソースコードにテストポイントの挿入を行います。続けて、ビルドを行い実行ファイルを作成し、実行ファイルを対象環境にディプロイ後、テストスクリプトを実行しつつテストレポート(実行ログ)を取得します。最後、取得したデータを解析し、テスト結果を集計しアウトプットするまでが、登録したJobの処理内容となります。
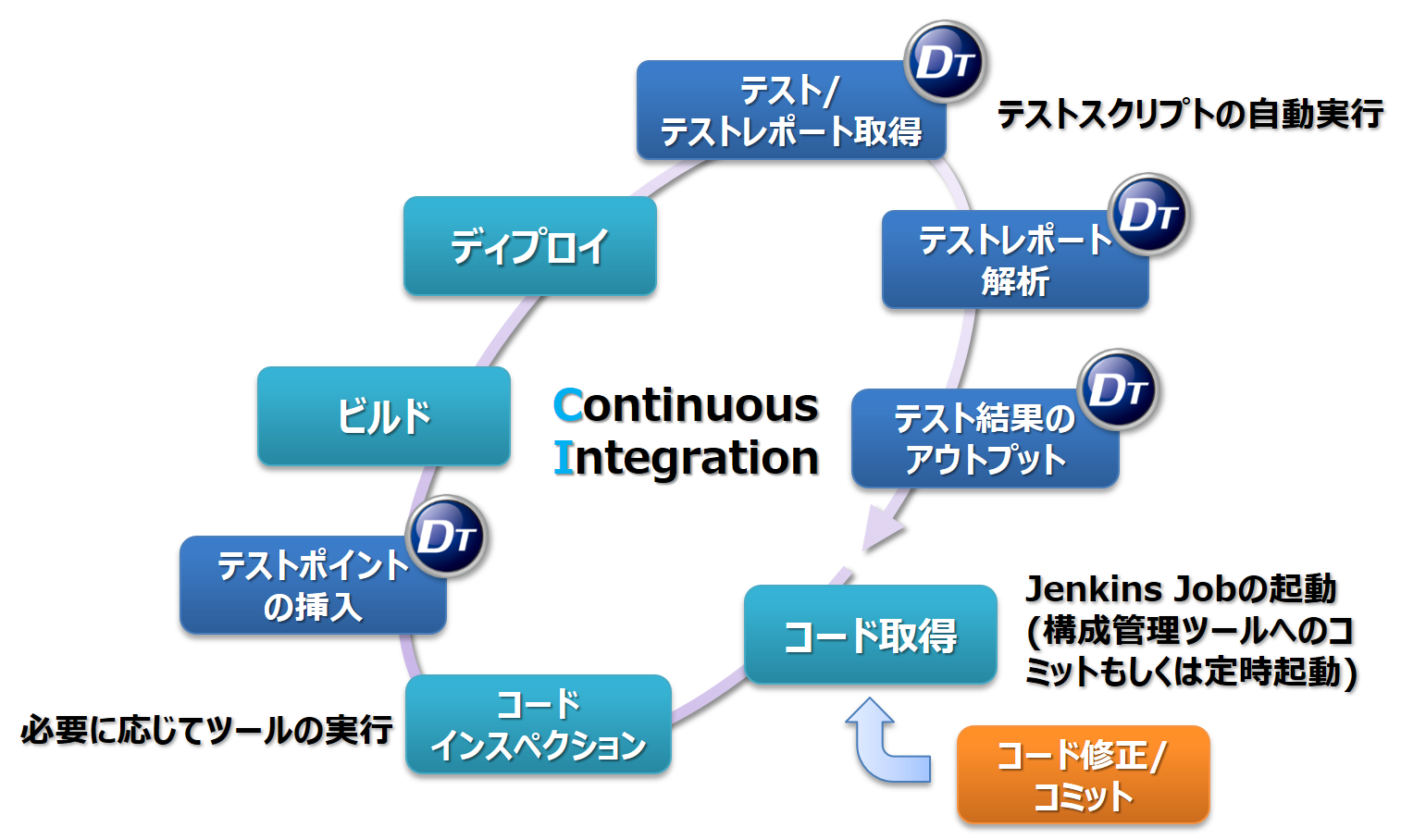
図1: 動的テストのCIサイクル
テストポイント挿入のための4W2H
何か行動や振る舞いを考えるとき、「5W2H」の観点で考えるとうまくまとめられると言われていますが、テストポイントの挿入の自動化も然りです。ただし、テストポイントの挿入の自動化では人は介在しませんので、「5W2H」のうちWhoを除いた「4W2H」の観点で考えると必要があります。それでは、いつどのタイミング(When)で、どこの(Where)フォルダで、どの(What)ファイルに、何のために(Why)、どうやって(How)、どのくらい(How many)テストポイントを挿入すればよいか考えて行きましょう。
When: いつ、どのタイミングで
Jenkinsでは、作成したJobを実行するタイミングを指定することができます。例えば、ある一定時刻になったらJobを走らせたり、構成管理ツールへのソースコードのコミットをトリガーにJobを走らせることもできます。ここで一番考えなくてはいけないのがテストの頻度とテストの時間です。開発人員が2,3人でテスト自体がものの数分で終わるのであれば、ソースコードのコミットごとにJobを走らせてもよいかもしれません。ですが、複数人がほぼ同時刻でコミットを行ったり、テスト時間が数時間に渡るようなケースでは、例えば、深夜1時からJobを走らせるような定時起動の方が有効なときもあります。動的テストの自動化に限らず、CIを考える上では「いつどのタイミングでJobを走らせるべきか」を考え設計を行う必要があります。
Where: どこのフォルダで
JenkinsでJobを作成するときは、そのJobが使用するワークスペースも指定します。このワークスペースはユーザーが日々ビルドで使用するワークスペースと同様の意味にはなりますが、ユーザーが使用するビルド環境と分けてJenkins Job用のワークスペースは作成した方がその後の管理が容易になります。また、Jobが走り始めた後、Jenkins側でも構成管理用のリポジトリにアクセスしてソースコードを取得させるための設定(次回詳細説明)も行います。さらに、フォルダ内のファイルに対してテストポイントの挿入、コードのビルド、ディプロイ・・・と続きますので、単なるフォルダの指定ですが、「どこのフォルダでJenkinsのJobに作業をさせるか」が意外と肝になります。また、日常のビルドとは異なる場所でビルドを実施しますので、ビルド時に必要なファイルやフォルダ構成も再確認しておくとその後の作業がスムーズになります。
What: どのファイルに
どのファイルに対してテストポイントを挿入するかを決める必要があります。確かに、全てのファイルに対してテストポイントを挿入することもできますが、それによる弊害がいくつかあります。まず考えられるのがリソースへの影響です。特に、リソースの限られている組込み開発では、テストポイント挿入によるコードの増加やテストポイントのオーバーヘッドの影響を受けやすいと言えます。また、リソースに余裕がある環境であったとしても、大量のテストレポートや解析結果の情報が一緒くたなってしまい、見たいデータがすぐに見つからなかったり、すぐに見つけられるように機能やカテゴリごとにデータの再集計が必要になるケースがあります。ですので、テストの目的と内容に合わせて、テストポイント挿入の対象となるファイルのグルーピングがされていると、その後の集計作業がスムーズになります。
Why: なぜ、何のために
何のためのテストなのかテストの目的を決めます。テストの目的によって、テストポイントの挿入の仕方が違って来るはずです。例えば、パフォーマンスを測定するときは、カバレッジ計測に必要なテストポイントは不要になります。むしろ、できるだけ素に近い状態でパフォーマンス測定するためにも不要なテストポイントは無効化しておいた方が得策です。
How: どうやって
特にカバレッジを計測するときは、コンパイルの対象となっていない(条件コンパイルによって無効化されている)コードへのテストポイントの挿入は避けた方が賢明です。実行されることのない個所にテストポイントが挿入された場合、カバレッジの数値が一定値以上上がらないことになります。このようなケースを防ぐための機能として、DTシリーズ製品では、テストポイントを挿入時に「条件付きコンパイル解析」を行うための設定があります。この「条件付きコンパイル解析」を使用することで、ソースコード上の必要な個所にテストポイント挿入することができカバレッジ計測時の不要な作業を削減できるので、「条件付きコンパイル解析」のための設定は必須とも言えます。また、特定の変数の変数の動きをモニタするときは、予めソースコード上にコメント行として、キーワードとセットで変数値を記載しておくことで、「テストポイントの自動挿入」時に変数値の出力のためのテストポイントも挿入することもできます。この変数値の挿入方法はおすすめの挿入方法の一つです。これらの詳細については次回以降詳しく解説いたします。
How many: どのくらい
何個テストポイントを入れるかです。リソースの状況によって挿入可能なテストポイントの数が制限されるため、テストの目的に応じて挿入するテストポイントの数を調整しなければなりません。いつどのタイミング(When)で、どこの(Where)フォルダで、どの(What)ファイルに、何のために(Why)、どうやって(How)テストポイントを挿入するかを決めたとしても、挿入するテストポイント数が制限されることによってその前提が崩れるかもしれません。テストポイント数が制限されたときの対策として、回数でカバーする方法が考えられます。テストポイントの挿入個所を変えて複数回テストを実施することになり、確かにテストの時間は増えますが人の手が介在しない自動化ですので、テスト時の作業工数という意味では、一回で実施できた場合と同等レベルの結果が得られるはずです。また、テスト内容を限定することで、テストの範囲を凝縮し、テストポイントの挿入数やテスト回数を減らす方法もあります。こちらの詳細につきましても、次回以降で詳しく説明したいと思います。
動的テスト自動化のためのシナリオ設計
静的テストの自動化と違い、動的テストの自動化では自動化のシナリオ設計が重要です。例えば、カバレッジ計測の自動化とパフォーマンスの測定の自動化では、挿入するテストポイントの位置や種類も異なりますし、テスト結果の集計の仕方も変わってきます。ですので、「テストポイントの挿入」から「テスト結果のアウトプット」までの首尾一貫した自動化シナリオ設計が必要になります。それでは、どのような観点でもってシナリオ設計すればよいか、「日々のソースコード変更に対するパフォーマンスの変化の監視」を例に考えてみましょう。
何を監視の対象とするか
エンハンス開発でベースコードを元に機能をインプリして行くとき、日々のソースコードの変更がどれだけパフォーマンスに影響を与えているかを早目に知りたいときがあります。パフォーマンスの変化は「時間」に表れますので、ある特定の個所の「処理時間」や「周期時間」を監視の対象とします。また、ツール側で負荷情報が算出可能な場合は、負荷に関する情報も監視の対象とします。以下は、監視対象の例です。
・プロセス、スレッド、タスクの占有率
・関数毎の処理時間
・特定処理の周期時間
・特定の2点間の時間
時間と負荷を計測するためのテストポイントの挿入
基本的に処理時間を計測するときには、少なくとも計測地点にテストポイントが挿入されている必要があります。また、負荷を計測するときは、負荷計測用のテストポイントもあわせて挿入しておきます。以下は、計測対象と計測に必要なテストポイントの組み合わせの例です。
・タスクの占有率 ⇒ 「イベントID出力ポイント」をOSのコードのコンテキスト切り替え処理に挿入
・関数毎の処理時間 ⇒ 関数の入り口と出口にそれぞれFuncIn, FuncOutのテストポイント挿入
・特定処理の周期時間 ⇒ 計測ポイントへのテストポイントの挿入と周期時間監視のためのプロパティ設定
・特定の2点間の時間 ⇒ 計測ポイントへのテストポイントの挿入と2点間実行時間の始点・終点設定
負荷計測のためのテストケースの準備
負荷を変化を見て行きますので使用するテストケースとしては、以下の三種類のデータが用意できるのが望ましいです。また、定点観測が基本となりますので、計測開始日から計測終了日までの間は、同じテストケースを使い続けるのが望ましいです。
・最大負荷を与えることができるテストケース(処理負荷が大きくなるパターンを複数用意)
・平均的な負荷となるテストケース(定常時のテストケースで代用可能)
・最小負荷となるテストケース(ターゲット機器側がアイドル状態のときの負荷が確認できればよい)
計測データ集計
データの集計では、監視対象となっている項目毎に「最大値」「最小値」「平均値」グラフにプロットして日々の変化を見て行きます。
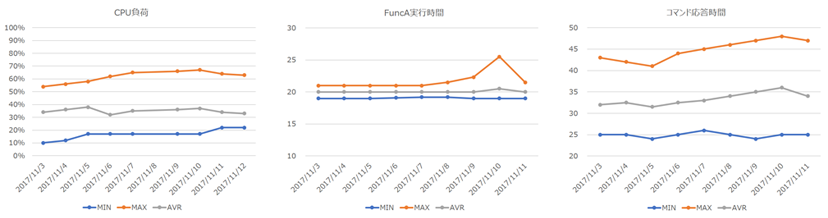
エンハンス開発では処理を追加するごとに徐々に負荷や処理時間の「平均値」が上がって行く傾向にありますが、特に、「平均値」の変化量に比べて「最大値」の変化量が大きくなるときは注意が必要になります。このように、数値の変化から何らかの異常が発見されたとしても、その当時のソースコードの変更履歴と異常のあった個所を照らし合わせることで、パフォーマンス低下の要因となっている個所の早期発見と手当がすぐにできます。
今回は、「日々のソースコード変更に対するパフォーマンスの変化の監視」を例に挙げましたが、「テストポイントの挿入」から「テスト結果のアウトプット」まで考えるべきことは多岐に渡ります。日々のカバレッジの変化を監視する場合でも同様です。ですが、このシナリオ設計をしっかりやっておくことでその恩恵は必ず受けられます。是非トライしていただきたいと思います。
最後に
いかがでしたでしょうか?
概念的な話が続いてなかなかツールの使い方の具体的な話が出て来なくて、本ブログを読んでいただいている方の中で少々物足りなさを感じている方もいるかもしれません。次回はがらりと変わって技術的な話がメインになりますのでご期待ください。
どんなツールも「適材適所」な使い方が望まれてはおります。この「適材適所」という言葉は、言うは易し行うは難しの言葉の一つではないでしょうか。「適材適所」の領域に辿り着くまでには、何度も「トレードオフ」が発生するはずです。都度よりよいジャッジが求められますが、これが難しくしている理由の一つかもしれません。よくよく考えてみると、実は、この判断能力はエンジニアであれば誰でも持っているのではないでしょうか。万能なデバイスであったり、夢のようなライブラリははありませんので、エンジニアは日々ハードウェアやソフトウェアを設計する上で、何らかの「トレードオフ」を経験していてそれをうまく裁いているはずですので。もしかしたら、ツールの「適材適所」な使い方は、エンジニアがその気になれば、意外とすぐに見つけられるのかもしれません。
バックナンバー
- 「動的テストの自動化を考える #1」- 動的テスト自動化のメリット
- 「動的テストの自動化を考える #2」- テストポイント挿入のための4W2H
- 「動的テストの自動化を考える #3」- CUIによるテストポイント挿入
- 「動的テストの自動化を考える #4」- DTシリーズ製品をJenkinsで動かすための準備
- 「動的テストの自動化を考える #5」- 動的テスト自動化のための設計
- 「動的テストの自動化を考える 番外編」- ESEC2018に出展したテスト自動化のデモ
- 「動的テストの自動化を考える #6」- Jobの設計
- 「動的テストの自動化を考える #7」- Jenkinsのパイプラインで何ができるか
- 「動的テストの自動化を考える 番外編2」- ET2018に出展したテスト自動化デモ
- 「動的テストの自動化を考える #8」- Jenkinsのパイプラインで動的テストの自動化を設計
- 「動的テストの自動化を考える #最終回」- Jenkinsのパイプラインで動的テストの自動化を実現
- 「動的テストの自動化を考える #最終回のおまけ」- Jenkinsによる動的テスト自動化の動画
![動的テストの自動化を考える [番外編]](https://hldc.co.jp/blog/wp-content/uploads/2017/08/img_auto_thinking-440x264.png)






