
エンジニアの皆さん、単体テスト、どう書いてます?
あたりまえですが、コード書きながらテスト考えなきゃいけないわけで、
キッチリ書こうとすると、なかなか工数膨らんでしまって大変タイヘン。
なにか上手いやり方はないものかChatGPTに聞いてみたら、
「網羅的に、独立性を保って、なるべく早い時期に、うまいことやればいいんじゃないですか」(大分省略しています)
だそうです。
うーん、もうちょっと実践的なHowtoないでしょうか。
ということで、うちのエンジニアたちから抽出した
「もう少し実践的な単体テストの心得」
を載せておきます。
みなさまのテスト効率化にお役立てください。
単体テストを作成する前に考えるべきこと
ここでの「単体テスト」の定義は、
「小さな単位(関数など)のプログラムが単体で正常に動作することをテストコードを用いて確認すること」
と定義します。
(手動で実施する単体テストもあるが、昨今重要度が激増しているリグレッションテストなどを考慮すると現実的ではない)。
テストコードを作ることは調べれば簡単にできるが、
実際はテストコードが作成しにくいコードに直面します。
つまりそもそも「単体テストを作ろう!」以前に問題があるわけです。
まず身に付けるべきは
「テストコードの書き方」では無く
「テスト対象コード」すなわち「プロダクトコードの書き方」
かと考えます。
単体テストを作りやすくするためのポイント
基本的なポイントとしては
- ビジネスロジックと環境に依存するものを分離する
- 何度繰り返しても同じ値が返るようにする
に分かれると考えています。
それぞれについて説明しますね。
ビジネスロジックと環境に依存するものを分離する
UIやファイル入出力、ネットワーク通信、DB処理などは、
それらの環境を構築した状態で単体テストを実行する必要があります。
なのでハードルがかなり高くなる。
また、単体テストの実行速度も遅くなるため(Slow Testというらしい)、
ビジネスロジックの単体テスト(Quick Test)とは分けて考えた方が良いです。
で、これらを分離するためには、
アーキテクチャ設計をきっちりしておくことが重要になります。
各レイヤーの依存関係を整理し、
依存の方向を決めておくことで
単体テストできる部分とできない部分を明確に分けておくわけです。
ここで重要なのは
「何を単体テストで担保しないのか」
という方針を決めること。
例えば
- DBへの読み書きは単体テストではなく結合テストで実施する
- 外部ライブラリの動作は事前調査で動作確認済みなので単体テストの対象には含めない
- UIは実動作で確認する
とかです。
※UIのテストコードとかも作れるけど、ここで言っている単体テストよりはハードル高めなので、すべてのプロジェクトで実施したほうが良いとは思わないです。
次に依存関係の作り方について。
様々な処理を組み合わせてシステムを作成していく以上、
全く依存させないものを作ることは不可能です。
例えばコマンドパケットをネットワーク通信で受信するケースを考えた場合、
- コマンドを受信する部分
- コマンドを解析する部分
- コマンドレスポンス送信の部分
はどうしても依存してしまう。
以下のクラス図のケースを考えてみましょう。
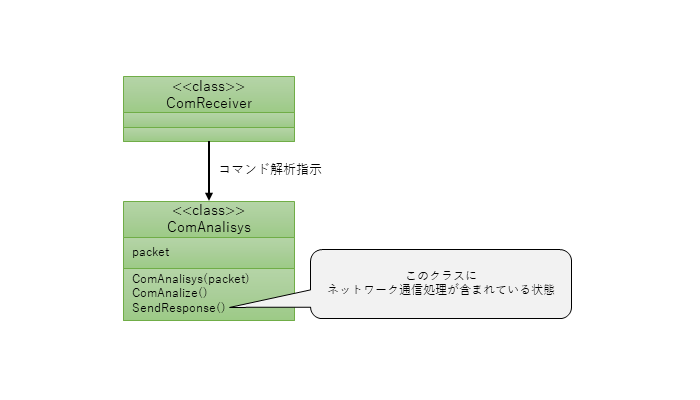
コマンドを解析する部分にはビジネスロジックが含まれるため単体テストの対象としたいが、
上記の場合だとレスポンス送信も一緒になっているため、
実際のネットワーク通信ができる環境でテストする必要がありますね。
つまり、通信用のライブラリを使っている場合は、そのライブラリが入っている環境である必要があります。
→ここで「単体テストが作れない・・・!」という絶望を味わったりします。
自力での解決策としては、以下のような感じです。
●Step1
ネットワーク通信部分をインターフェースとして定義することで、
実体の差し替えができるような状態にする。
これによりネットワーク送信を行うコマンドレスポンスクラスとは直接的には依存しなくなる。
●Step2
コマンド解析クラスを生成する際にレスポンスクラスの実体を外から注入する。(これをDependency Injection:通常DIという)
これで柔軟にテスト環境を変えることができる。
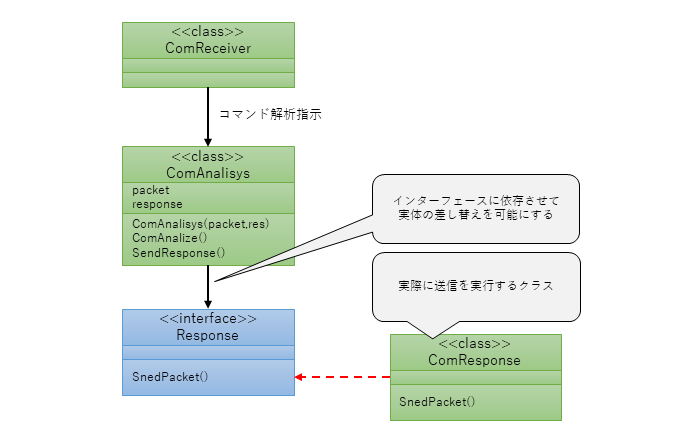
テスト時のクラス図は以下のようなイメージ。
ネットワーク通信部分を切り離したことでコマンドの解析部分にのみフォーカスしてテストが実施できます。
※ネットワーク通信の他にDBやファイル入出力なども同様に分離しましょう。
実際には様々な依存関係があるので、こんな簡単に解決することはないですが、
こういった依存の整理を繰り返せば、テストしやすい環境を構築することができるでしょう。
それでも、開発が進むにつれて色々と違和感や不吉なにおいを感じることがありますが、
そういった場合はリファクタリングして都度修正していくべきでしょう。
最初から完璧なものは作れないので、ある程度の妥協も必要と思います。
何度繰り返しても同じ値が返るようにする
単体テストは一般的に処理結果と期待値の比較によりOK、NGを判断するため、
ある引数を与えて返ってくる結果が毎回異なるのでは単体テストになりません。
よって毎回結果が異なる処理はビジネスロジックを含む処理とは分離する必要があるわけです。
例えば以下のような処理が入っているものは要注意。
- 今日の日付を取得
- 乱数を算出
- 上記のような処理を含む関数を呼んでいる
上記のような処理を分離する方法としては、
引数としてそれらの乱数を渡せるようにしておくのが最も簡単です。
何をテストするべきか
あたりまえかもしれませんが、以下は確認したほうが良いです。
- 同値分割
- 境界値分析
- 無効値/異常系
でも手動でやると手数が多くて結構面倒だったりします。
最近流行ってる気がするテストの自動化環境なんかを構築してみると結構ラクなんですけどね。
境界値分析みたいな、手数の勝負になりがちなテストは特に。
あと、無効値とか異常値とかはそもそも実動作だと容易に再現できないケースも多い。
たとえば、火災報知器のセンサー制御みたいなのを書いたとして、
テストで実際に火災おこすわけにはいかないわけです。
その他にも条件網羅(C2カバレッジ)なんかも確認できるとよいですね。
そういえば、
うちの会社が無効値/異常値も手軽にテストできるようなテスト自動化ツールを作ってるので、
良かったら見ていってください。
安くパパっと始められるらしいです。
単体テストのメリット・デメリット
かんたんにですが、まとめておきます。
メリット
- 不具合を早期発見できる(つまり、結合テスト以降に不具合を発見した際に問題の切り分けがしやすくなる)
- 不具合の修正が容易
- リグレッションテストができる
- テストを意識することで整理された実装ができる
- テスト仕様が更新されやすい
- コードに自信が持てる
デメリット
- 開発工数の増加による開発者の負担増
- 開発者のレベル感による品質のばらつきが出る
レガシーコードに対して
いろいろ書きましたが、
アーキテクチャ設計をきっちり行って最初から整理されたプロジェクトを作っていく
というのが一番良いのは間違いないわけです。
なんですが、どうにもならないときがあるのも事実です。
脈々と開発されてきた、九龍城のごとき巨大コードの開発を引き継がねばならないときとか。
そういうときは、基本的に「諦めが肝心」というか、
既存のコードにあまり変更を加えないようにしつつ、
新規追加コードはちゃんと単体テストやっていくようにするのが、ちょうどいいかもしれません。
もしくは、単体テストの段階であっても積極的に「動的テストツール」なんかを活用していくのも手です。
※動的テストって何?という方は↓をご参照ください。









