
今回は「パイプライン」です。Jenkins2.0から標準で使えるようになったとはいえ、この「パイプライン」のメリットは何でしょうか?Jenkinsの「パイプライン」をググってみると、そのメリットの感じ方は人それぞれのようですが、概して「Pipeline as Code」にメリットを感じている方が多いようです。自動化の潮流でCI/CDが当たり前となった昨今、CI/CDを構築する手順も複雑になり、スクリプトをちょっと変えただけでもビルドが通らなくなったり、テストが回らなくなったりしたことが多くなってきていると思います。そこで出てくるのが「Pipeline as Code」という考えです。本ブログのテーマでもある「動的テストの自動化」も、実際に自動化のためのスクリプトを組んでいくと、あれこれ手順が増えていきスクリプトも複雑化する傾向にあります。そう考えると、「動的テストの自動化」にも「Pipeline as Code」という考えはマッチするのではないかと考えました。そこで、今回から3回に渡り「Pipeline as Code」に基づく「動的テストの自動化」の最善の形を考えていきたいと思います。
CONTENTS
「Pipeline as Code」とは
よく「○○ as Code」という表現をあちこちで見かけますが、そもそも「Pipeline as Code」とはどういうことでしょうか。一般的に、「○○ as Code」といった場合、「○○をコードで管理する」という意味になります。「○○ as Code」の代表的な例として、「Infrastructure as Code」があります。まずは、「Infrastructure as Code」の考え方から見ていきましょう。
Infrastructure as Code
Wikiによると、「Infrastructure as Code」は次のように書かれています。
Infrastructure as Code(IaC) というのは、物理的なハードウェア構成やインタラクティブな設定ツールの使用ではない。コンピューティング・インフラ(プロセス、ベアメタルサーバー、仮想サーバー、など)の構成を管理したり、機械処理可能な定義ファイルを設定したり、プロビジョニングを自動化するプロセスである。なお、定義されたファイルはバージョン管理システムで保持することもある。従来、手動のプロセスではなくスクリプトや宣言的な定義によって行われていたが、IaCの開発は今では、宣言的なアプローチに焦点が当てられている。
出典元: Infrastructure as Code – ウィキペディア
一見、スッと入ってこない表現ではありますが、平たく言えば、「環境構築手順がコード化されていれば、バージョン管理もできるしメンテ作業や検証作業、派生開発への流用が楽になる」ということになるでしょうか。
Pipeline as Code
では、「Pipeline as Code」はどうでしょう。そもそも、「Pipeline as Code」という表現はJenkins 2.0がリリースされた2016年頃から盛んに使われていたことばのようで、最近(2018年9月時点)では、”Pipeline”というと、”as Code”の意味も含んでしまっているのか、本家サイトにある「Jenkins User Document」には「Jenkins as Code」とう記述はありません。しかしながら、「Jenkins as Code」で検索してみると、当時の「Jenkins User Document」の一部なのか、次のような記述が見つかりました。
Pipeline as Code
Introduction
Pipeline as Code describes a set of features that allow Jenkins users to define pipelined job processes with code, stored and versioned in a source repository. These features allow Jenkins to discover, manage, and run jobs for multiple source repositories and branches — eliminating the need for manual job creation and management.
出典元: Pipeline as Code – Jenkins User Document
こちらは、「パイプラインとして実行するJobをコードで制御・管理することで、複数のリポジトリにまたがるJobも一元管理可能」という意味になるでしょうか。
以上のことから、「パイプラインで行う内容とその手順」をコードで管理することによって、「Pipeline as Code」には、「Infrastructure as Code」と同様に、次のようなメリットがあると言えます。
- ・コード化することによりバージョン管理が可能になる
- ・バージョン間の差分情報が問題発生時の手掛かりとなる
- ・バージョン管理されることにより属人化が排除される
- ・派生開発モデルへの流用・再利用が可能になる
「Pipeline as Code」を「動的テストの自動化」にどう適用するか
「Pipeline as Code」の目指すところとメリットがわかったところで、次は、「動的テストの自動化」に対してどのように適用すべきかを考えてみたいと思います。第2回で示したように、DTシリーズ製品を使用して「動的テストの自動化」のCI環境を構築した場合、図1のような流れになります。
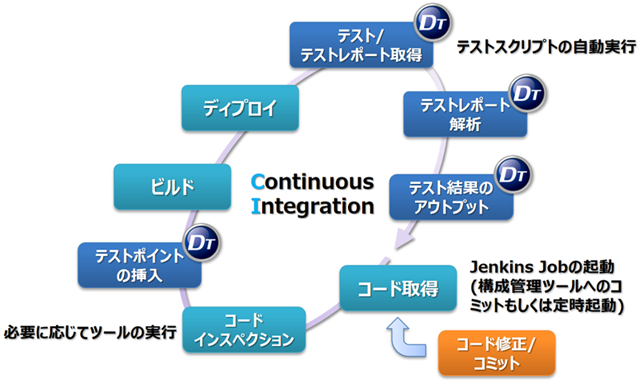
図1: 動的テストのCIサイクル
このCIのサイクルでは、ソースコード取得後の「コードインスペクション」から「テスト結果のアウトプット」まで、大きく7つのフェーズに分かれています。この7つのフェーズは、適度に処理内容が分かれており、各フェーズ毎にパイプラインで実行するJobとして記述すると都合がよさそうです。派生モデルが発生したときの再利用性という意味では、このフェーズ単位で可読性のあるコードを書いておくことで保守性が高まりそうです。では、改めて各フェーズで実行する処理内容を整理してみたいと思います。
コードインスペクション
基本的に、取得したコードを静的解析ツールに掛けるフェーズとなります。コーディングルールのチェックやソースコードの構造解析や静的解析を実行することになります。
テストポイントの挿入
DTシリーズ製品を使用した場合、このフェーズでテストポイントの挿入を行います。テストポイントを挿入する前に、対象とするファイルや挿入アルゴリズムは決めておく必要があります。何らかの要因で、テストポイント挿入時にエラーが発生したときは、このフェーズのログにテストポイント挿入時のエラーメッセージとして残す必要があります。
ビルド
ソースコードのビルドを行うフェーズです。ビルド中に発生したエラーはフェーズのログとして残す必要があります。
ディプロイ
実行ファイルやイメージをターゲット環境にディプロイするフェーズです。組込み機器ではファームをターゲット基板に転送して書き込むフェーズとなります。ディプロイ時にエラーが発生したときは、このフェーズのエラーとして残します。
テスト・テストレポート取得
テストケースを流すと同時に、DTシリーズ製品でテストレポートを取得するフェーズとなります。
テストレポート解析
一連のテストが完了した後に、取得したデータを解析するフェーズです。
テスト結果のアウトプット
解析したデータを集計しデータを見えやすく加工するフェーズです。
各フェーズで行う処理の明確化もさることながら、各フェーズでエラーが発生したとき「どの処理を実行したときに何のエラーが発生したか」を明確に残せる工夫がされていると一段と保守性が高まりますので、次回はこれらを意識したパイプラインのコーディングを行っていきたいと思います。
最後に
今回取り上げました「Pipeline as Code」という考え方ですが、意外と「動的テストの自動化」に向いている思うのは筆者だけでしょうか。「動的テストの自動化」もフェーズ分けしてやるべきことを挙げていくと、改めていろんなことをやっているなとその複雑さを実感してしまいます。たとえ自動化であってもメンテに掛かる工数が増えてしまうと本末転倒になってしまいますので、再利用性の高い「動的テストの自動化」向けの「Pipeline as Code」を構築していきたいと思います。
バックナンバー
- 「動的テストの自動化を考える #1」- 動的テスト自動化のメリット
- 「動的テストの自動化を考える #2」- テストポイント挿入のための4W2H
- 「動的テストの自動化を考える #3」- CUIによるテストポイント挿入
- 「動的テストの自動化を考える #4」- DTシリーズ製品をJenkinsで動かすための準備
- 「動的テストの自動化を考える #5」- 動的テスト自動化のための設計
- 「動的テストの自動化を考える 番外編」- ESEC2018に出展したテスト自動化のデモ
- 「動的テストの自動化を考える #6」- Jobの設計
- 「動的テストの自動化を考える #7」- Jenkinsのパイプラインで何ができるか
- 「動的テストの自動化を考える 番外編2」- ET2018に出展したテスト自動化デモ
- 「動的テストの自動化を考える #8」- Jenkinsのパイプラインで動的テストの自動化を設計
- 「動的テストの自動化を考える #最終回」- Jenkinsのパイプラインで動的テストの自動化を実現
- 「動的テストの自動化を考える #最終回のおまけ」- Jenkinsによる動的テスト自動化の動画









