
IoT機器の普及が進んでいる昨今、ネットワークに関連した機能が充実しているLinuxを搭載する動きが加速しています。そういった動きを受け、これまで別のOSやOSレスで開発していた機器もLinuxでの開発に置き換わったという方が多いのではないでしょうか。しかし、Linuxでのデバッグ方法について、ノウハウがなく悩んでいる方も少なくありません。以下のグラフは以前弊社で開催したセミナー参加者を対象に、Linuxで開発時のデバッグの現状についてアンケートを取ったものです。
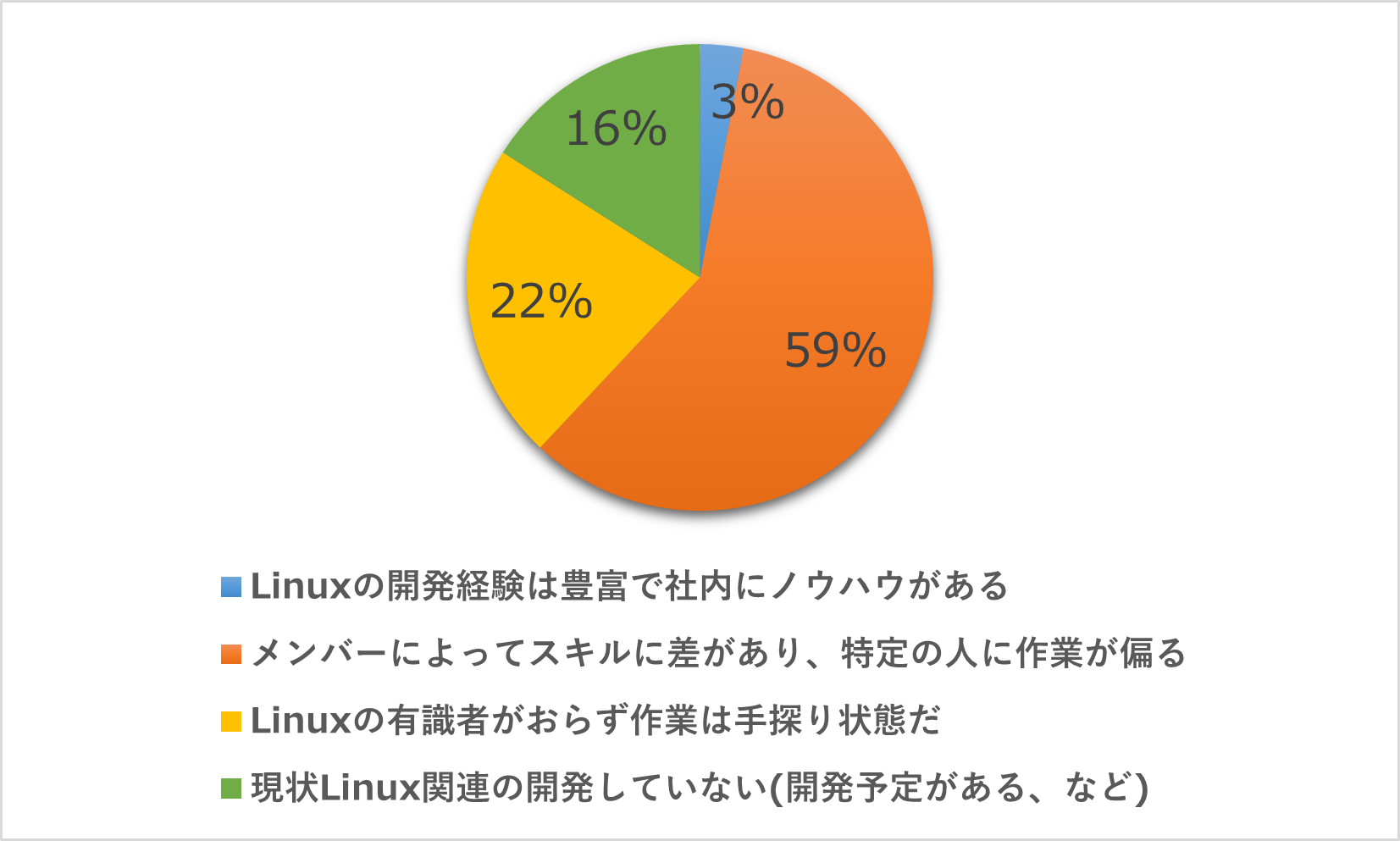
これを見ると、Linuxでのデバッグのノウハウがあると回答した方は全体のわずか3%でした。Linuxでの開発プロジェクトを進めるうえでデバッグスキルの不足を感じている方が多いことが分かります。
そこで今回は、多くの開発者が直面するバグの特定やメモリリーク、パフォーマンス問題といった悩みを解決するため、GDB(デバッガ)やプロファイリング、メモリリーク検出など、Linuxのデバッグコマンドやツールをいくつかピックアップし、その使い方を説明します。この記事が、具体的なデバッグ方法を知りたい、実行したいという方のヒントになれば幸いです。
CONTENTS
デバッガ – GDBコマンド徹底解説
GDBとは?Linuxデバッグにおける役割
Linuxのデバッガと言えば、代表的なモノがGDBコマンドです。Linuxでは標準でインストールされているためほとんどの環境で使用できます。以下のように、デバッガに求められる機能はすべて標準で搭載されています。
- ブレークポイントの設定
- ステップ実行
- 変数値の参照/書き換え
- 関数呼び出し履歴の表示(バックトレース)
GDBの使用イメージは以下のようになります。ターゲット側で起動しているGDBサーバにアクセスし、GDBの各種コマンドを打ち込むことで、GDBサーバを介してターゲットプログラムをデバッグできます。
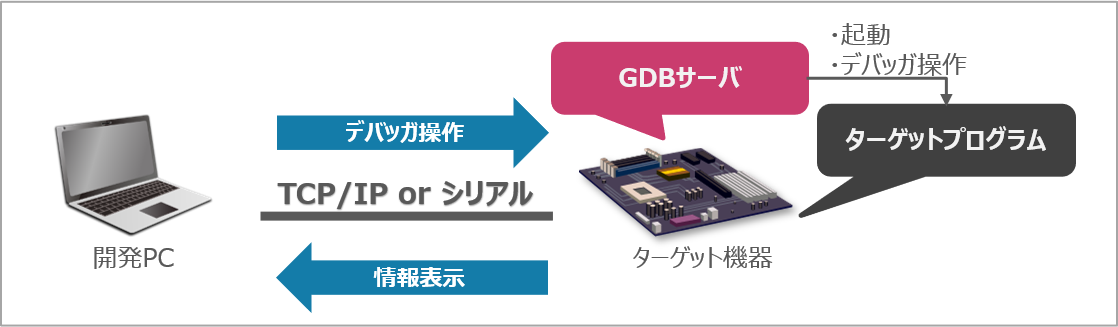
GDBの使用フローをまとめると以下のようになります。

GDBの使い方(起動・ブレークポイント・ステップ実行)
「GDBの具体的な操作方法を知りたい」「Linux環境での実践的なデバッグ手順を求めている」 開発者の皆様に向け、ここではGDBを使ったデバッグの基本手順と、実務で必須となるコマンド操作を解説します。
GDBを使用する場合は、ビルドする際に以下のように”-g”を付加する必要があります。またデバッグ時に最適化がかかってしまうとステップ実行の際にコードの把握がしづらくなるため、以下の例では“-O0”フラグを付加しています。
> gcc -g -O0 app.c -o app
ビルド後、ターゲットにデプロイしたら、上記のフローの通りまずはGDBサーバをターゲット機器上で起動します。以下のようにPCのIPアドレスとポート番号、デバッグしたい実行ファイル名を指定します。
> gdbserver 192.168.10.30:2345 ./app
その後開発PCからGDBサーバにアクセスします。なお、下記の例ではarmを搭載したターゲット機器を使用しており、GDBコマンドで実行ファイルを指定したうえでターゲット機器のIPアドレス・ポート番号を指定してアクセスしています。
> arm-linux-gnueabi-gdb ./app ・・・ > (gdb) 192.168.10.40:2345
ここまで完了すると、いよいよGDBの主要コマンドを使ったデバッグが可能です。ブレークポイントを設定したうえでターゲットアプリケーションをGDBサーバを介して実行します。

ブレークポイントが設定されていれば該当箇所で処理が停止します。ブレークポイントを張る、ステップ実行を行うなど、基本的な操作は以下の表のようになります。これらのコマンドを使いこなすことが、Linuxデバッグの第一歩です。

変数の値を確認する場合は以下のコマンドを使用します。

また、バックトレースやソースコードを表示する場合のコマンドは以下のようになります。

GDBを使って不具合発生箇所を特定する
GDBとコアダンプを使用して、セグメンテーションフォルトなどの不具合の発生箇所を特定できる場合があります。ちなみにコアダンプとは、ターゲットプログラムが強制終了したときにその際のメモリの状態を記録したファイルです。これをGDBで読み込むことによって、どの処理を実行したときに強制終了したかを判別できます。
手順1: コアダンプファイルの生成設定
ターゲット機器側でコアダンプが生成されるようにするためには以下のコマンドを使用して事前に設定しておく必要があります。
> ulimit -c unlimited
“ulimit”とは、GDBなどデバッグに限らずターゲット機器で使用できるメモリやファイルの最大サイズ、同時に実行できるプロセス数などユーザーが使用できるリソースを制限するコマンドです。“-c”でコアダンプを指定し“unlimited”で無制限を指定すると、コアダンプファイルが生成されます。なお、この場合ビルド時に“-g”オプションを指定しておけばGDBサーバを起動しなくても構いません。
セグメンテーションフォルトが発生すると、以下のように“core dumped”と表示され、コアダンプファイル(core)が生成されます。

手順2: GDBによる解析
開発PCからGDBサーバを介してコアダンプファイルを読み込むと、セグメンテーションフォルトの発生箇所、呼び出し履歴、変数値の確認が可能です。

このようにしてGDBコマンドを使用して不具合の原因を直接解析することができます。
プロファイラ – gprofコマンドの使い方と解析手順
gprofとは?
GDB同様Linuxに標準でインストールされているプロファイラです。関数の実行時間だけでなく、呼び出し回数の測定や構造表示もできるようになっています。以下のように“-pg”オプションを付加してビルドします。
> gcc -pg app.c -o app
ターゲットアプリケーションを実行すると、以下の“gmon.out”というファイルが生成されます。なお、ターゲットアプリケーションを正常終了させる必要があるため、使用できるシチュエーションは限定される可能性があります。
このファイルはターゲット機器側に生成されますが、クロスプラットフォームで読み込み可能です。開発PCにファイルをコピーし、コピーしたディレクトリ上で以下のように”gprof”コマンドを使用すると結果が表示されます(“app”はオブジェクト名です)。
> gprof app
gprofを使って処理時間を解析する
gprofコマンドを実行すると、以下のように関数ごとの実行時間を解析できます。その関数のそのままの実行時間はもちろん、サブ関数(解析対象から呼び出されている関数)の時間値を差し引いた実行時間も表示されます。
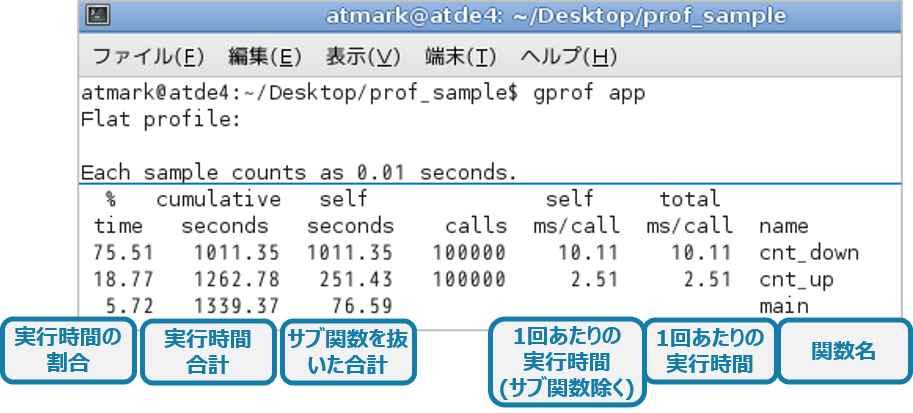
gprofコマンドを使用して表示される結果はこれだけでなく、関数階層を加味した形での表示も可能です。関数の呼び出し構造を把握できるよう、右端に表示されている関数の項目は呼び出し構造を加味してインデントされています。また、呼び出し回数や処理時間の占有率なども分かります。
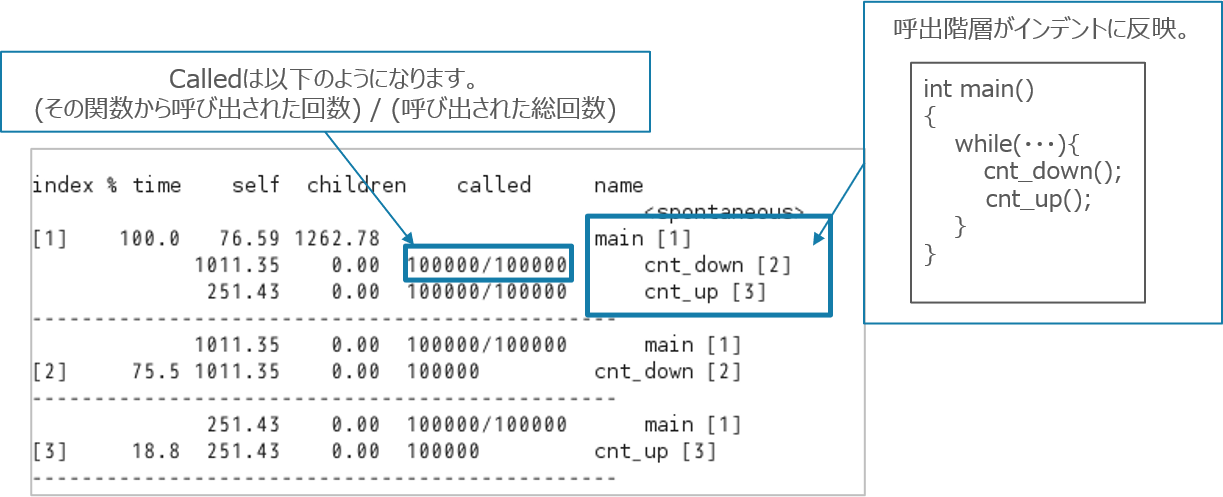
これを使用することで、意図しない関数の呼び出しがないか、あるいはどのパターンの呼び出しフローで時間がかかっているのか、などを把握することができます。
gprofは標準的なツールとして利用可能ですが、プログラムの正常終了が必要である点やサンプリング精度に制約があるため、より詳細かつ高度な解析や、カーネルレベルのプロファイリングが必要な場合は、perfなどの代替ツールを検討するとよいでしょう。
CPUの負荷やメモリ使用量の把握 – TOPコマンドの活用
プロセスごとのCPUの占有率やメモリ使用量の把握には、TOPコマンドが便利です。TOPコマンドを実行すると、以下のようにターゲット全体のCPUやメモリの使用量が表示されます。その下のリスト部分には、プロセスごとにメモリやCPUの使用率が表示されます。
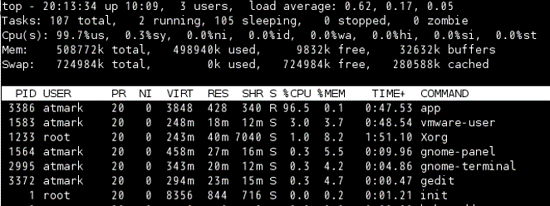
表示データは定周期で更新されるため、実際にターゲットアプリケーションを実行させながらリアルタイムに値を確認できます。例えば、ある特定の操作を行ってその際のCPUの占有率を確認したり、その操作が終わったらCPUの占有率が下がるのか、下がらなければ何か意図しない処理が操作後も行われているのではないか、といった観点で確認できます。
メモリリーク検出 – MEMWATCH
MEMWATCHはmallocやfreeなどメモリの割り当て・解放関数をフック(MEMWATCHが監視できるモノに置き換え)し、メモリリークやメモリのアクセス違反(多重開放)を検出するのに有効なコマンドです。例えばTOPコマンドで確認しているとメモリの使用率が徐々に増えていくといった現象が発生する場合、どの処理によってメモリリークが発生しているかをMEMWATCHで確認できます。
Githubから必要なファイルをダウンロード
これまでのGDBなどと異なり、事前にGitHubからMEMWATCHの処理に必要なソースファイル・ヘッダファイルを入手しておきます。そして入手したヘッダファイル(memwatch.h)を、対象のソースファイルにインクルードします。
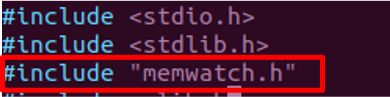
そのうえで、以下のように“-DMEMWATCH”、“–DMW_STUDIO”をオプションを付加して入手したmemwatch.cをターゲットのソースファイルと一緒にビルドします。ここまでで準備が完了です。
> gcc -DMEMWATCH –DMW_STUDIO memwatch.c xx.c ・・・
メモリリークを検出する
実際にターゲットのアプリケーションを実行すると、以下のように”memwatch.log”が生成されます。

このファイルをそのまま開けば、ターゲットアプリケーションが実行された際のメモリの確保・解放状況を確認できます。

メモリリークやアクセス違反などが、どこで発生したのかすぐに把握することが可能です。
MEMWATCHも有用なツールですが、より一般的なメモリデバッグツールとしてValgrindもあります。Valgrindは、再ビルドの必要がなく、既存のバイナリに対してより詳細なメモリリーク検出が可能です。
メモリリークの兆候を確認する方法
もしメモリリークが疑われる場合は、本記事で解説するデバッグツールを使う前に、まずはTOPコマンドなどでその兆候を確認することも重要です。メモリの使用量が継続的に増加しているなどの現象を確認したい場合は、以下の記事をご覧ください。
関連記事:組込みLinuxのメモリ使用率をリアルタイムに監視する方法
ツールを使ってまとめて解析 – 動的テストツール DT+
これらのコマンドは、それぞれ別個にオプションを使用してビルドしたり、解析も別々のコマンドで実行したりする必要があり、実はなかなか手間がかかります。そのような課題は弊社の動的テストツールDT+シリーズを使用することにより解決できます。
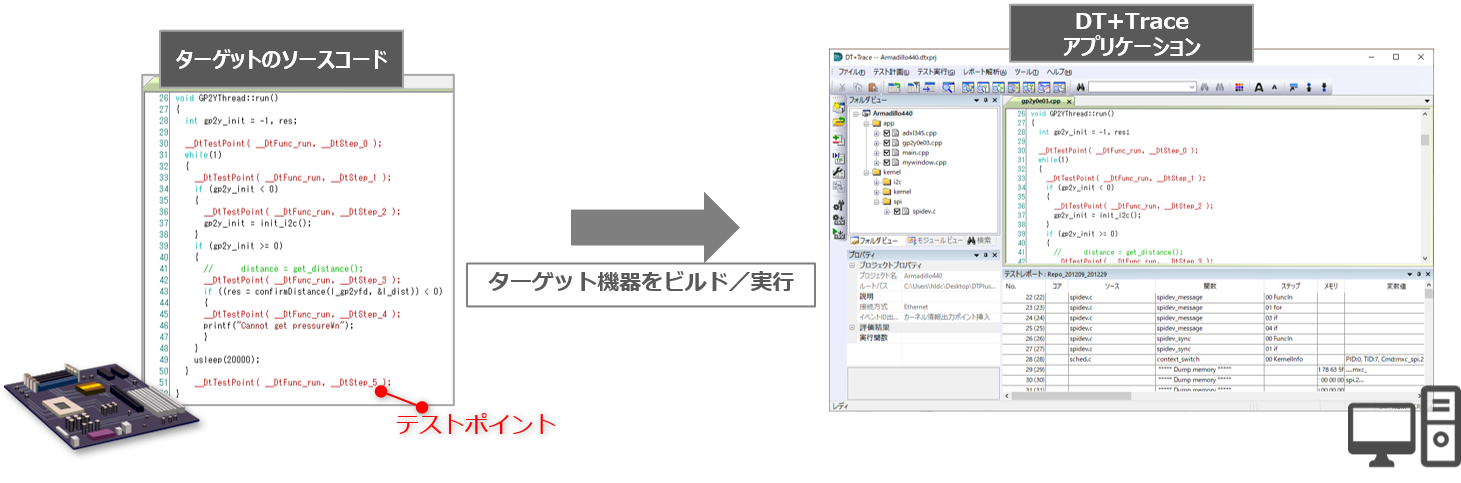
printfデバッグのようにテストコードを仕込み(DT+が自動で実行)、実際に動作させた際にログを取得するツールとなっています。取得したログはアプリケーションが自動で解析され、例えば実行経路は以下のように表示してくれます。
それだけでなく、処理時間の解析やCPUの負荷が高いときの処理の確認など、様々な解析が一度のログ取得で行えます。そのため、デバッグコマンドのように、見たいものに合わせていちいちログを取得する手間がかかりません。何よりGUIで操作できるため、開発者誰もが直感的に解析できるのが大きなメリットです。
アプリケーション層とカーネル層をまとめて解析
また、今回紹介したデバッグコマンドではアプリケーション層のみが解析対象となるため、カーネル層にあたるデバイスドライバなどの処理はさらに別途解析方法を考えなくてはなりません。このあたりもDT+Traceを使用すればアプリケーション層とカーネル層のログを同時に取得し解析することができます。このような利点から、Linuxの開発現場でも多く使用されています。
まとめ
開発メンバーにこれらのコマンドを浸透させて、チーム全体として運用していくことは、多くの方々が苦労されている課題です。またprint文を駆使して力業で行うという方も少なくありません。この記事の内容が、ターゲット機器の内部処理を解析する手段を増やすきっかけになれば幸いです。また現状の手法に限界を感じている、誰でも確実にデバッグできるようにしたい、そんな方は弊社のツールを選択肢に入れてみませんか。
【 無料でみられる! 】
動的テストツールDT+ デモ動画
ソフトウェア開発者のための動的テストツール「DT+」をご紹介する動画です。
ソースコードの実行によりログを収集し、多彩な解析機能によりソフトウェアの動作をこまかく見える化。たった数クリックの解析で、関数遷移や変数の変動、カバレッジをグラフィカルに表示します。本動画では、そんなDT+の導入手法から実際の解析の様子まで、基本的な使い方をデモンストレーションいたします。
手動デバッグやコマンド操作の煩雑さから解放され、効率的な解析を実現したい方はぜひご覧ください。









